
大前端的时代,前端的重要性已经已经无可置疑。在某些情况下,前端甚至决定了产品的成败。体验优良,性能卓越的前端产品留得住用户,体验糟糕的前端即使后端能力再优秀,最后也难逃被用户卸载的命运。
为了追求前端的性能,前端需要对构建出来的js负责,确保发送给用户的js没有一行多余。这样才能确保最快的加载时间。但是,这个目标通常是比较难做到的。其中一个原因是程序员对webpack构建出来的js都包含什么不是十分清晰;另外一个原因是:大部分项目用了很多轮子(npm包),以确保项目可以按时上线。这些轮子虽然可以使用,但是代码不一定是精简的,我们又对这些代码没有控制能力。即使有些冗余,很多人也都只是忍了。
这里以我们的项目为例介绍我们是如何解决这两个问题的。
发现系统问题
首先,我们需要分析一下我们的项目都用了哪些库,打包出来都多大。
我们用了一个工具webpack-bundle-analyzer。
npm install过后,把这个插件告诉webpack。这样webpack打包的时候webpack-bundle-analyzer就能对打包的文件进行统计。
// webpack.config.js
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
{
// ...
plugins: [
new BundleAnalyzerPlugin()
]
}
这是我们项目的文件打包情况。
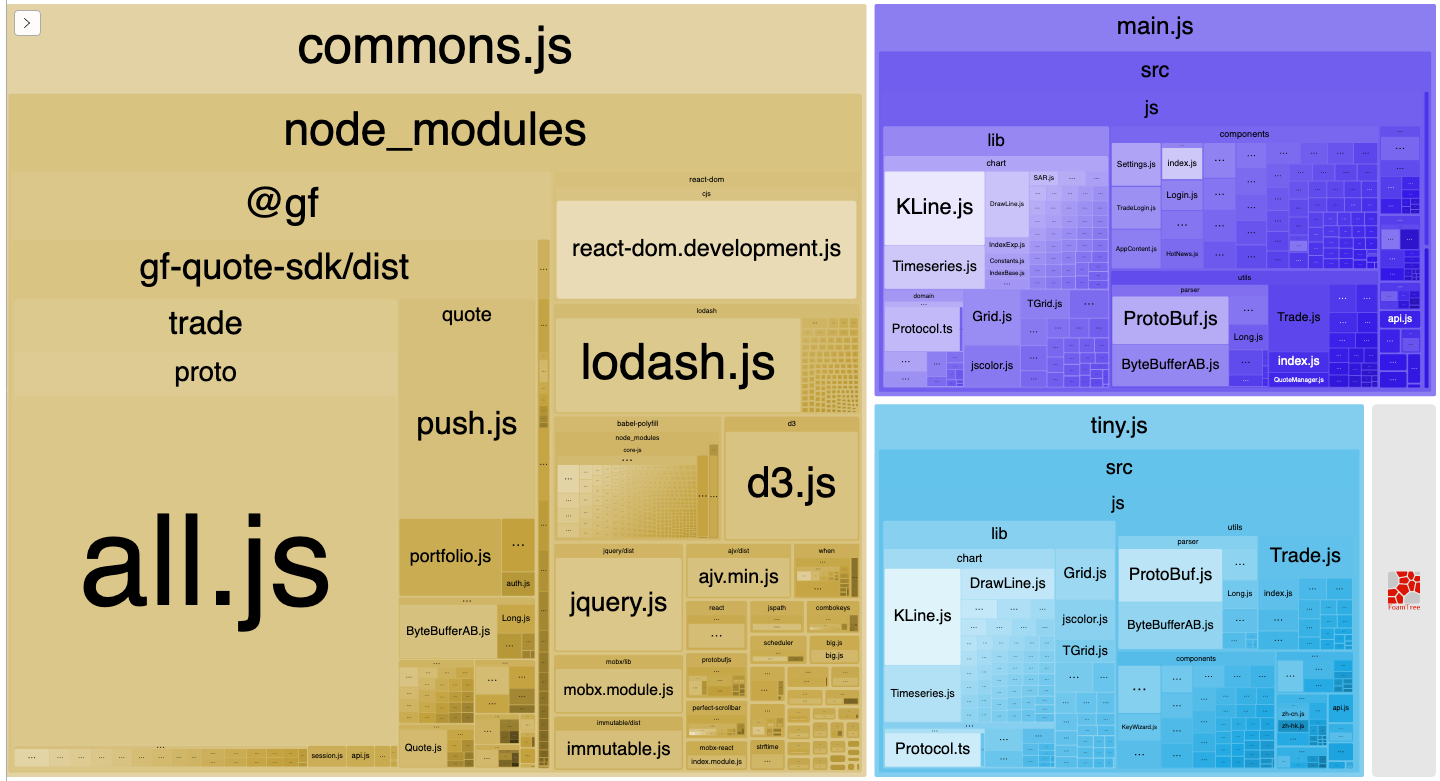
左边的commons.js都是来自于npm里面的文件,可以发现左边一个巨大的all.js占用了commons.js将近一半的体积。这个文件足足有18w行。优化这个文件的体积定能收到不错的效果。遗憾的是这个文件我们手工修改不了,是protobuf工具生成的。
优化protobuf生成的js
protobuf是一个流行的google的序列化库。我们的后台接口定义在.proto文件中,然后通过protobufjs这个工具转换.proto文件为.js文件,就是这个all.js文件。因为后台每次开发新业务需求会新增加协议文件,所以这个文件从上线以来就呈一直增长的趋势。
这是我们的构建命令pbjs -t static-module -r trade --sparse -w es6 -p ./proto/proto3.0 --no-create --no-comments --no-delimited --no-beautify --no-verify file1.proto file2.proto file3.proto file4.proto。最后面几个是输入文件,每次都往后面增加。
现在要优化这个文件就要把这个文件打散,按业务逻辑生成多个js,需要加载某个业务的时候再加载相应的js文件。
好在我们的protobuf已经是按业务层级划分的。
biz1
file1.proto
file2.proto
biz2
file3.proto
file4.proto
...
理论上,只需要按业务划分,多次调用pbjs命令生成多个js就行。
像这样:
pbjs biz1/file1.proto biz1/file2.proto > biz1.js
pbjs biz2/file3.proto biz2/file4.proto > biz2.js
事实上这还不够。看下生成的biz1.js文件。(biz2.js文件结构类似)
import * as $protobuf from "protobufjs/minimal";
const $Reader = $protobuf.Reader, $Writer = $protobuf.Writer, $util = $protobuf.util;
const $root = $protobuf.roots.trade || ($protobuf.roots.trade = {});
export const gf = $root.gf = (() => {
const gf = {};
gf.client = (function() {
const client = {};
client.biz1 = (function() {
const biz1 = {};
/// ...
return biz1;
});
return client;
});
gf.common = (function() {
/// ...
});
return gf;
})();
export { $root as default };
这个文件带了部分ES6语法,但是命名空间都是通过js的自执行函数生成的。这种叫做js的module pattern,在IE6的年代,这种写法曾大行其道。
注意到中间的gf.common了么?由于biz1/file1.proto文件引用了项目的公共common.proto文件,这块逻辑会在每个文件中都存在。我们最好把它都删除掉,一个文件有就好了。这是第一个我们要做的。
还有一个极其严重的问题:这个module pattern没有考虑到命名空间分散在多个文件的情况。biz1.js文件声明了gf.client.biz1,加载了biz2.js文件后,直接被gf.client.biz2替换,而不是把biz2模块附加上去。
我们把嵌套去掉,这样方便看出问题。这是三个嵌套的命名空间。
gf.client.biz = (function() {
const biz1 = {};
/// ...
return biz1;
})();
gf.client = (function() {
const client = {};
/// ...
return client;
})();
gf = (function() {
const gf = {};
/// ...
return gf;
})();
看,每层嵌套都是一个新的object!
假如每个object声明的时候可以先看下是否存在,就可以做到模块融合的效果。把上面三处嵌套改为如下的结构的代码。
gf.client.biz1 = (function() {
const biz1 = $root.gf.client.biz1 || ($root.gf.client.biz1 = {});
return biz1;
})();
gf.client = (function() {
const client = $root.gf.client || ($root.gf.client = {});
return client;
})()
gf = (function() {
const gf = $root.gf || ($root.gf = {});
return gf;
})()
要做到对js的这两处改动可不容易。因为js是高度结构化的。来个批量替换,万一替换到字符串里面的东西了不是砸着自己的脚了么?
使用babel修改protobuf产出文件
这里我们请出修改js文件的神器babel。咦?Babel不是个ES6转换工具么?对!但是它还是有很多轮子可以拆下来做点事情的。
我们需要用到它的四个轮子,把我们的转换工具跑起来。
- @babel/parser: 这个库吃掉我们的js文件,生成结构化的js的语法树。
- @babel/traverse: 这个库是用来遍历上一步生成的语法树的。
- @babel/types:定义了语法树中出现的各种类型,字符串,表达式,标识符等等。
- @babel/generator:这个库吃掉js语法树,生成js文件,大功告成。
四个轮子使用的大致流程如下:
const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const generator = require('@babel/generator').default;
// 1. parser转换js文件为语法树
let ast = parser.parse(code, {
sourceType: 'module'
});
let traverser = {
// 2. 更改js语法树的逻辑放这里
};
// 3. 遍历语法树
traverse(ast, traverser);
// 4. 转换语法树为js
return generator(ast).code;
删除部分js代码
我们先来完成删除common块的任务。对!就是这块:
gf.common = (function() {});
这是一个赋值的表达式,所以我们用ExpressionStatement捕获这块。但是表达式是很多的,还要要进行筛选。
左边得是一个MemberExpression,还得是gf.common。
const traverser = {
ExpressionStatement(path) {
let left = path.node.expression.left;
if (left && left.type == 'MemberExpression'
&& left.object.type == 'Identifier' && left.object.name == 'gf'
&& left.property.type == 'Identifier' && left.property.name == 'common') {
// 这就是gf.common = ...没错了
path.remove();
}
},
};
替换部分js代码
第二个修改点,我们要追踪嵌套的js模块,还要手工生成一段js代码,替换老的代码。
这是我们要修改的代码:
const gf = {};
通过如下代码找到修改的目标语句。这句是一个VariableDeclaration,长度为1,因为这句只有一个变量的赋值;
而且一定要node.kind == 'const'且右边是个ObjectExpression,且没有任何属性。
let pathes = ['$root'];
const traverser = {
VariableDeclaration(path) {
if (path.node.declarations.length != 1) {
return;
}
let decl = path.node.declarations[0];
if (path.node.kind == 'const' && decl.init.type == 'ObjectExpression' && decl.init.properties.length == 0) {
pathes.push(decl.id.name);
// 这里识别出目标语句
}
}
};
请注意这里我们用了pathes变量识别了深度递归的时候的模块名字,这样我们可以得到['$root', 'gf', 'client', 'biz1']这样一个数组。
有了这个数组,我们通过递归调用如下genMemberExp函数,获得$root.gf.client.biz1这段js语法树,这是一段嵌套的MemberExpression。
function genMemberExp(pathes) {
if (pathes.length == 1) {
return t.Identifier(pathes[0]);
}
return t.MemberExpression(
genMemberExp(
pathes.slice(0, pathes.length - 1),
),
t.Identifier(pathes[pathes.length - 1])
);
}
好了!万事俱备只欠东风。我们把新的语法树替换老的语法树。
// 用新生成的js替换老的
path.replaceWith(t.VariableDeclaration(
'const',
[t.variableDeclarator(
t.Identifier(decl.id.name),
t.logicalExpression(
'||',
memberExp,
t.AssignmentExpression(
'=',
genMemberExp(pathes),
t.ObjectExpression([]) // 空object {}
)
)
)]
));
最终,通过generator把我们修改过的的语法树转换为js。从而砍掉了将近一半的commons.js。
总结
js文件大小对前端体验有决定性的作用。在做优化的时候,除了常规的优化手段,首屏,懒加载等,用babel做一些构建期的js优化是一个新的思路。有些时候甚至能达到立竿见影的效果。