全文检索是一种在大规模数据集中查找关键词的技术。它是一种基于文本内容的搜索方法,通过索引文本中的每个单词或词组,使其能够快速定位和检索相关文档。
全文检索的基本原理是将文本数据集中的每个文档进行分词,生成一个包含所有单词或短语的索引。这个索引通常是一个倒排索引(Inverted Index),它将每个单词或短语映射到包含该词或短语的文档列表。当用户提交一个查询时,全文检索系统会根据查询词在索引中进行匹配,找到相关的文档并按照相关性进行排序,最后返回给用户。
全文检索技术广泛应用于各种领域,包括搜索引擎、数据库系统、文档管理系统等。它提供了高效的文本搜索和信息检索能力,用户可以通过关键词或短语快速找到所需的文档或信息。
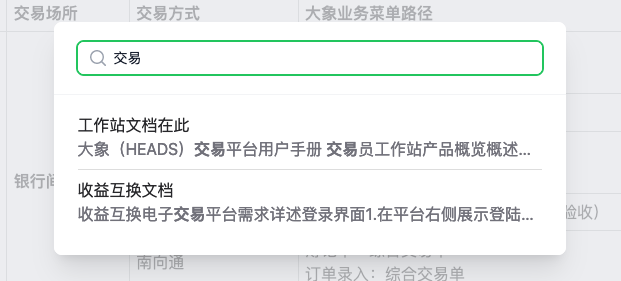
本文产生的背景也是为了搜索。给我们的一个产品文档应用增加一个搜索功能,根据前端输入的关键字进行更高级,更丰富的检索。
对比选型
- LIKE:LIKE是SQL的一个语句,实施简单,但是功能却极其有限。它只能在db的一个字段中进行全字符匹配,多个空格就匹配不上了。人工智能时代了,这样的体验简直说不过去呀。
- Algolia: 另外一种低成本但是高效的搜索是使用algolia云服务。目前不少前端系统的文档中都能看到它的身影。vuejs.org vitejs.dev react.dev。这个云服务会去index你的页面,然后让你的网站具备搜索功能。你只需要加上几行接入的js代码。但是很遗憾由于我们的应用是内网应用,algolia无法访问我们的页面并检索。
- DB full-text index: 常见的db系统也是支持全文索引的,如postgres, mysql。但是有两个条件:一个是db版本,一个是你可能需要修改db启动配置。这两个在不同的团队不一定都能满足。我们中心的mysql支持全文索引但是不支持中文分词ngram。所以并不能使用。
- sqlite full-text index: sqlite是一个本地数据库,一般常用于客户端,终端上的数据存储,比如微信客户端,当你在微信里搜索一个聊天信息的时候你可能就是在用sqlite。这个方案跟上一个类似,但是有个本质不同。sqlite是一个本地的数据库+一个动态链接库。不需要DBA权限。你控制一切。
- 把文档丢给Chatgpt,用GPT来开发AI助手。这个可能是未来的趋势,实施技术难度也略高,本文暂时不考虑。
综上所述,我们的最终方案可能是3或是4。如果是3,我们需要升级db,大动干戈,这很可能不行,这个应用场景并不是一个重要的业务功能。如果是4,数据存在于一个文件上,后台多实例之间数据将不能同步。幸运的是,这个对我们并没什么问题。因为我们希望在测试环境单实例上编辑数据,然后把数据文件一股脑发布出去。生产上根本不用修改。接下来我们动手开干!
sqlite和FTS5扩展
sqlite的全文检索使用FTS扩展,FTS5是最新的标准。在开启了FTS5的表中,文本数据被分割为一系列词条,并根据这些词条创建倒排索引。倒排索引是一种数据结构,通过将词条映射到其出现的位置的方式,使得在搜索过程中可以快速定位到相关文档。幸运的是FTS5是内置的,可以直接使用。首先通过sqlite命令行工具用如下的sql语句创建一个支持全文搜索的虚拟表。
CREATE VIRTUAL TABLE IF NOT EXISTS page USING fts5(name, desc, body);
创建出来的表,会有不只出现一个表,其他表都是FTS5的倒排索引实现,不需要考虑。
sqlite> .table
page page_content page_docsize
page_config page_data page_idx
然后我们往里面插入一些数据
INSERT INTO page (name, body) VALUES ('a', 'apple is nice');
INSERT INTO page (name, body) VALUES ('b', 'banana is nice');
INSERT INTO page (name, body) VALUES ('c', 'orange is nice');
最后我们使用关键字nice apple查询这个表
SELECT snippet(page, 1, '<b>**', '</b>**', '', 50) snippet, [page.name](http://page.name) FROM page where body MATCH 'nice apple';
输出是
<b>apple</b> is <b>nice</b>|a
可以看到
- 输入的关键词被分割成词条并查询。
- snippet这个函数很方便。网页上不是要高亮关键词么,这里的就是给搜索关键词加个标签扩起来。
- 使用FTS5的sql语句都是非标准的sql,因此没必要用ORM,比如typeorm, prisma之类
还有两个问题需要思考:
- 创建这个表的时候我们并没有指定字段类型,这意味着这个表是专门为全文索引设计的。在实际使用中我们要用这个表关联其他表的记录。
- 插入中文之后,全文索引并没用处。这个是因为一个叫做分词器的东西不支持中文。
接下来我们分别解决这两个问题。
FTS5表关联原始数据
解决FTS5表和原始数据关联的方法是使用两个表,一个存储全文索引,一个存储原始记录。如下sql,前两个创建了两个表,page表是原始数据表,page_fts是全文索引表。要搜索用page_fts,要增删改查用等普通操作用page表。
# 创建数据表
CREATE TABLE IF NOT EXISTS page (id INTEGER PRIMARY KEY, name TEXT, desc TEXT , body TEXT, slug TEXT);
# 创建fts表
CREATE VIRTUAL TABLE IF NOT EXISTS page_fts USING fts5(name, body, content=page, content_rowid=id);
上面fts5函数中通过content指定原始数据表,content_rowid指定原始数据表主键。
另外在原始数据表更改的时候数据要同步内容到page_fts表吧,不然会查到删除过的数据。这就是后面创建的三个增删改触发器的作用。
# 创建触发器
CREATE TRIGGER IF NOT EXISTS page_ai AFTER INSERT ON page BEGIN
INSERT INTO page_fts(rowid, name, body) VALUES ([new.id](http://new.id), [new.name](http://new.name), new.body);
END
CREATE TRIGGER IF NOT EXISTS page_ad AFTER DELETE ON page BEGIN
INSERT INTO page_fts(page_fts, rowid, name, body) VALUES ('delete', [old.id](http://old.id), [old.name](http://old.name), old.body);
END
CREATE TRIGGER IF NOT EXISTS page_au AFTER UPDATE ON page BEGIN
INSERT INTO page_fts(page_fts, rowid, name, body) VALUES ('delete', [old.id](http://old.id), [old.name](http://old.name), old.body);
INSERT INTO page_fts(rowid, name, body) VALUES ([new.id](http://new.id), [new.name](http://new.name), new.body);
END
接着我们解决中文搜索问题。
libsqlite增加中文分词器
sqlite的默认分词器是拉丁语系的。分词器通过空格分词,并把每个单词加入索引。但是中文等东亚语言由于没有明显的分词记号,所以分词也更复杂。常用的一些分词器可以是基于字的,就是把每个字做索引,缺点是索引会大一些,优点是如果输入不完整的词条也是能找到的。分词器也可以是基于词的,这样索引不至于很大,但是更复杂,需要基于统计,深度学习的分词器。
这里我们用一个开源的组件wcicuTokenizer。wcicuTokenizer是微信开源的wcdb中sqlite分词插件,由于sqlite也是安卓系统的一部分,微信用sqlite做本地消息的缓存,所有有这个东西存在。但是安卓跟正常系统还是不一样,有些地方是需要改动才能在正常的linux中运行,比如icu的依赖需要修改为动态链接库的形式,另外需要升级到FTS5最新的扩展标准。我从下文中找到基于FTS5的分词器。改吧改吧。
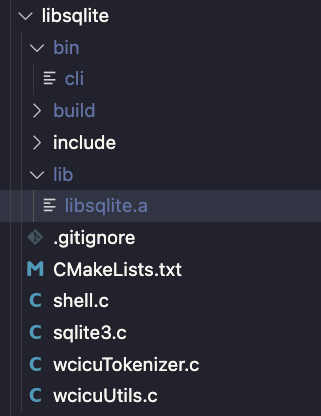
把wcicuTokenizer.c wcicuUtils.c这两个文件加入到从官方下载的libsqlite工程,再修改sqlite3.c文件把上面两个文件的导出函数fts5WcicuCreate, fts5WcicuDelete, fts5WcicuTokenize加入到分词器列表中。
struct BuiltinTokenizer {
const char *zName;
fts5_tokenizer x;
} aBuiltin[] = {
{ "unicode61", {fts5UnicodeCreate, fts5UnicodeDelete, fts5UnicodeTokenize}},
{ "ascii", {fts5AsciiCreate, fts5AsciiDelete, fts5AsciiTokenize }},
{ "porter", {fts5PorterCreate, fts5PorterDelete, fts5PorterTokenize }},
{ "trigram", {fts5TriCreate, fts5TriDelete, fts5TriTokenize}},
{ "wcicu", {fts5WcicuCreate, fts5WcicuDelete, fts5WcicuTokenize}},
};
接下来,我们通过cmake命令启动编译。
cmake -B build
cmake --build build
CMake是一个C/C++的构建工具,通过读取CMakeLists.txt里的构建命令构建项目。 -B命令创建了平台的编译工程,比如vs项目,xcode项目。--build命令执行平台的构建任务。
完事之后,产生如下两个文件,lib/libsqlite.a是静态库,bin/cli是sqlite命令行工具。我们可以用bin/cli工具执行之前的建库命令检验成果。且建库参数需要增加tokenize参数指定wcicu。
# 建库命令需要增加tokenize参数指定wcicu和语言zh_CN
CREATE VIRTUAL TABLE IF NOT EXISTS page_fts USING fts5(name, body, content=page, content_rowid=id, tokenize='wcicu zh_CN');
node-sqlite3 NAPI插件构建
有了静态库还不算完,还需要打通js调用侧。nodejs使用NAPI addon的方式调用C++方法。需要把上面的libsqlite.a跟node插件部分连接编译出一个.node后缀的动态链接库,才能通过js调用上文产出的sqlite功能。接下来需要修改sqlite3 npm包。
把sqlite3这个包下载下来,从这个包的package.json文件可以知道。
- 这个包是node-gyp包,需要安装node-gyp工具,和C++编译器。
- 这个包通过prebuild包把二进制上传到了github上,所以项目中使用这个包的时候直接下载了二进制扩展,所以不用重新编译。
node-gyp是基于Google的gyp工具的一套编译系统,gyp最早被用于chrome浏览器的编译,它类似于CMake,也是nodejs官方推荐的编译工具。它的配置文件存在于binding.gyp文件中,是一种类似于json的格式。
在这个包中执行如下命令,启动node插件编译。
npm install --build-from-source --sqlite=$(realpath ../libsqlite) --sqlite_libname=sqlite
../libsqlite目录内放置的是上一步骤产出的静态库文件。--sqlite参数的意思是传递了libsqlite的目录作为参数给node-gyp编译系统。
由于wcicuTokenizer动态链接了icu库做unicode处理,这里还需要修改binding.gyp,在连接器参数上加入对libicu的依赖。
"libraries": [
"-l<(sqlite_libname)",
"-licuuc",
],
"conditions": [
[ "OS=='linux'", {"libraries+":["-L/app/icu/usr/local/lib", "-Wl,-rpath=/app/icu/usr/local/lib"]} ],
[ "OS=='mac'", {"libraries+":["-L/opt/homebrew/opt/icu4c/lib", "-Wl,-rpath,/opt/homebrew/opt/icu4c/lib"]} ],
],
完事后,我们得到node_sqlite3.node文件,这个文件就是我们需要的支持中文分词的node插件。
nodejs工程整合
接下来我们需要在项目中使用上面产出的node插件。我们考虑两个选择:
- 把上面的包改个名字发到内部的npm。另外还有个二进制产物问题。由于这个包在公司内部使用,二进制产物通过prebuild发到github上就不可能了。我们只能打包进npm包里。这需要在mac linux windows三个平台编译出插件,以确保npm包的跨平台性。
- 还有一个选择就是任然依赖官方的sqlite3(js毕竟是一样嘛)。然后通过prepare命令patch二进制产物。
这里我们选择第二种更为简单的方式进行整合。在package.json中加入postinstall命令,覆盖插件为我们定制过的版本。
"scripts": {
"postinstall": "cp node-sqlite/sqlite3/build/Release/node_sqlite3.node ./node_modules/sqlite3/build/Release/node_sqlite3.node"
}
接下来我们就可以通过js语句插入记录和查询结果了。下面是插入的函数,数据还是往page表中插,之后会通过trigger触发page_fts表中新增数据。
export async function insertFts(data: {
name: string;
desc: string | null;
content: string;
slug: string;
}) {
const stmt = db.prepare("INSERT INTO page (name, desc, body, slug) VALUES (?, ?, ?, ?)");
stmt.run(da[ta.name, ](http://data.name)data.desc, data.content, data.slug);
}
查询的时候我们直接查询page_fts表。
export async function queryFts(term: string) {
return new Promise((resolve, reject) => {
db.all(SELE`CT snippet(page_fts, 2, '<b>', '</b>', '', 50) snippet, page.name, page.slug FROM page_fts LEFT JOIN page on page.id == page_fts.rowid WHERE page_fts MATCH ?, [t`erm], (err, rows) => {
if (err) reject(err);
resolve(rows);
});
});
}
这样我们的全文搜索就做好了。🎉🎉